
Ph.D. in Computer Science
Information Sciences Institute (ISI), University of Southern California
4676 Admiralty Way, Marina del Rey, CA, 90292
Email: bvu687@gmail.com
Resume
Information Sciences Institute (ISI), University of Southern California
4676 Admiralty Way, Marina del Rey, CA, 90292
Email: bvu687@gmail.com
Resume
Software
Below is a list of some software that I developed over the years.
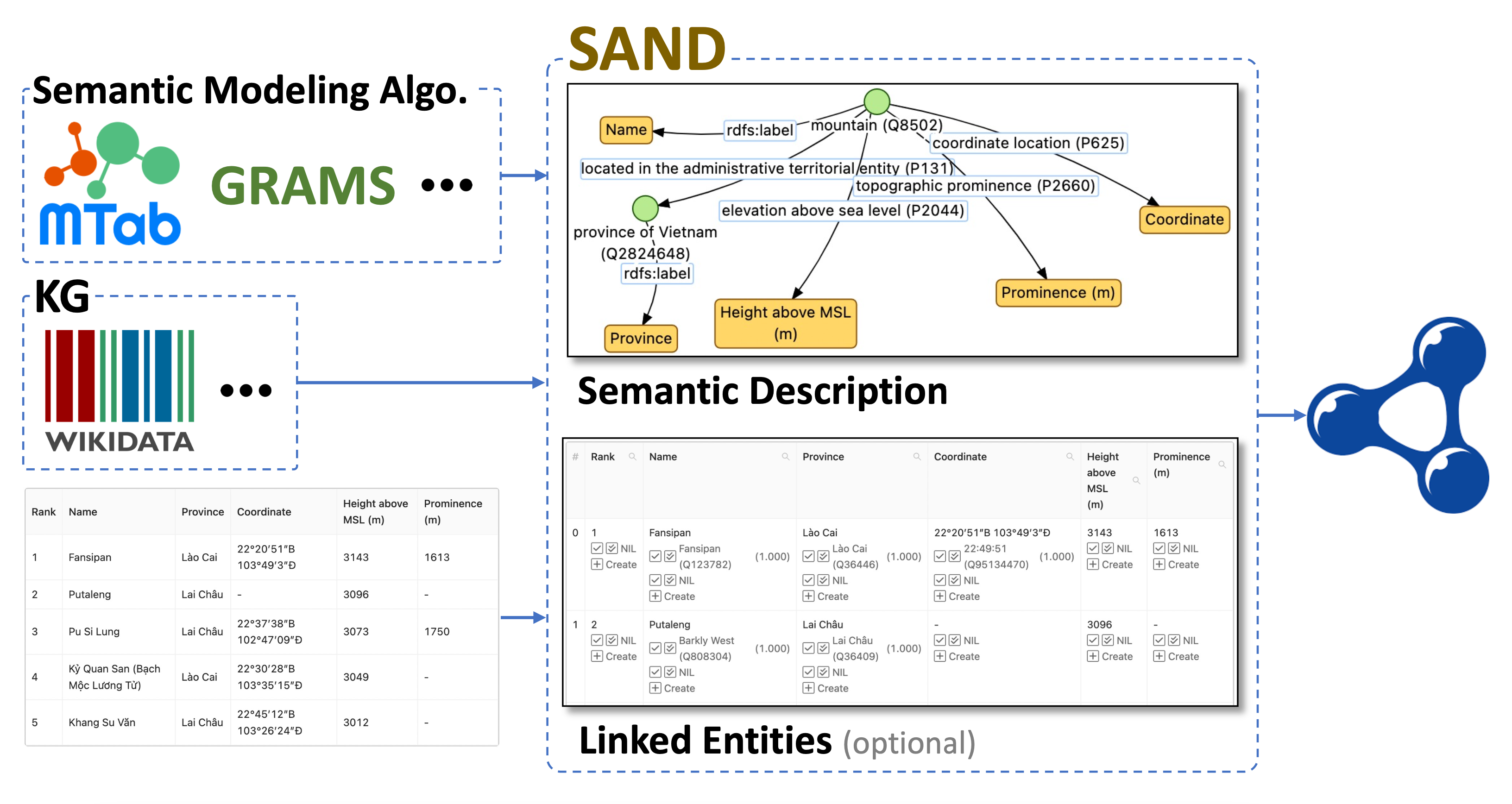
SAND: A Tool for Creating Semantic Descriptions of Structured Sources
A tool for creating semantic descriptions semi-automatically. SAND makes it easy to integrate with semantic modeling systems to predict or suggest semantic descriptions to the users, as well as to use different knowledge graphs (KGs). Besides its modeling capabilities, SAND is equipped with browsing/querying tools to enable users to explore data in the table and discover how it is often modeled in KGs.
Paper Github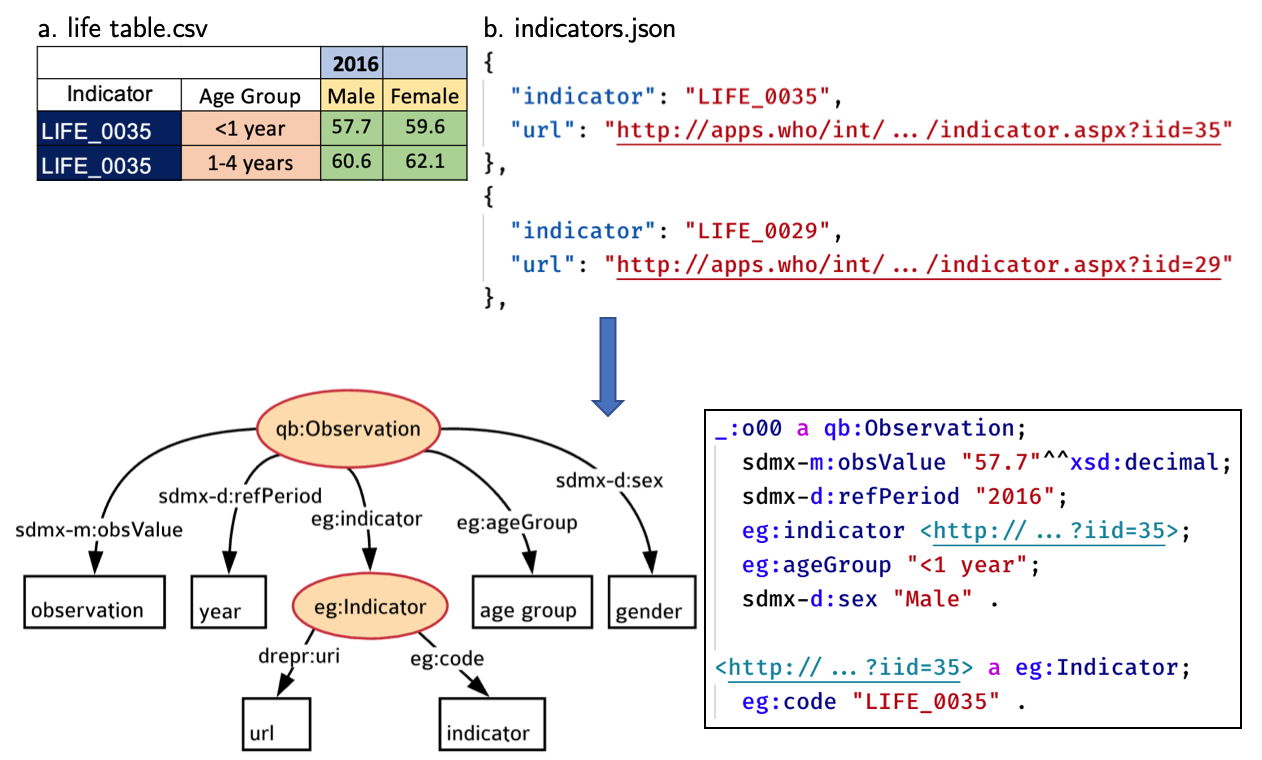
Dataset Representation Language for Reading Heterogeneous Datasets to RDF or JSON
- Reading public datasets is a laborious task and frequently requires to write custom code because data are often stored in many different formats (CSV, JSON, Spreadsheet, NetCDF, etc) with different layouts (row-based, matrix, hierarchy).
- To address the problem, we create D-REPR, a language to represent heterogeneous datasets, and a very efficient D-REPR processor to read the datasets from their own formats to a common representation.
Streamlit Bridge
Streamlit components that allow client side (javascript) to send data to the server side (python) and render HTML content without being processed by Markdown.
Github