
Information Sciences Institute (ISI), University of Southern California
4676 Admiralty Way, Marina del Rey, CA, 90292
Email: bvu687@gmail.com
Resume
Biography
Binh Vu is a scientist and an engineer. Binh received his Ph.D. in Computer Science from the University of Southern California in 2024 (advised by Prof. Craig Knoblock) and his Bachelor of Engineering in Computer Science from Ho Chi Minh University of Technology (top 1%, honor program). His research focuses on machine learning techniques for knowledge graph construction, especially on methods to understand the semantic description of data sources for automated data integration. Recently, his work centers on semi-supervised approaches for domains with limited labeled data by leveraging pretrained large language models. Binh also has extensive experience in software engineering. He worked for Rakuten to develop a fraud detection system and interned for Meta to develop an in-house automated machine learning platform. His experience includes software architecture, full-stack development, and large-scale distributed systems. He enjoys designing and optimizing systems to make them more efficient. His research and open-source software have been used in several real-world projects.
Projects
-
Ongoing
-
Critical minerals are essential components in modern technology and the global economy. MinMod uses AI and Machine Learning techniques to extract and create grade/tonnage data from scientific publications, databases, and NI 43-101 reports.
-
2023-24Python Pytorch Knowledge Graphs Machine Learning NLP
-
Completed
-
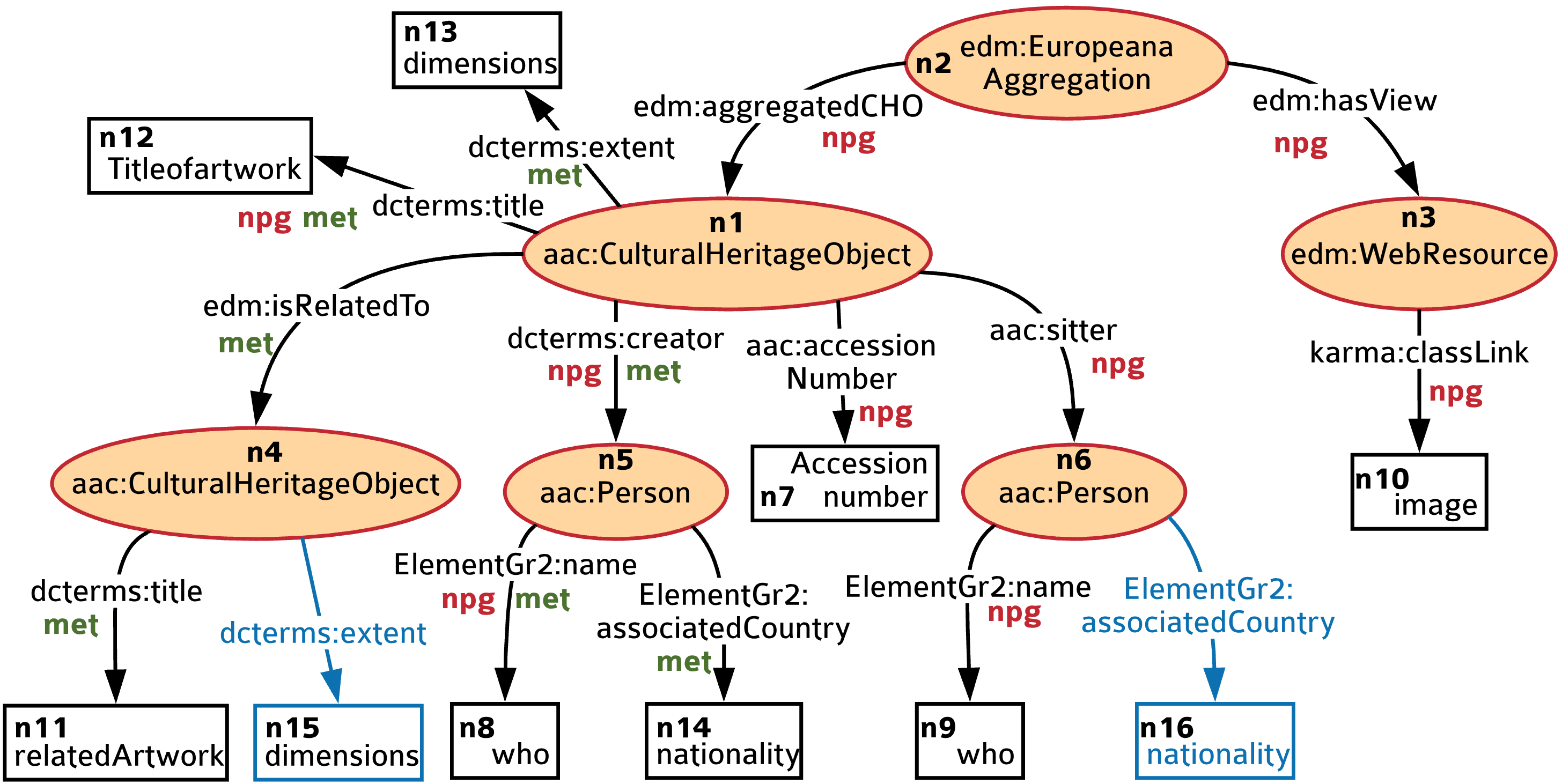
Generating semantic descriptions of data sources for automatic data integration and knowledge graph construction.
-
2017-24Python Rust Scala Pytorch Knowledge Graphs NLP Deep Learning Language Models
-
Completed
-
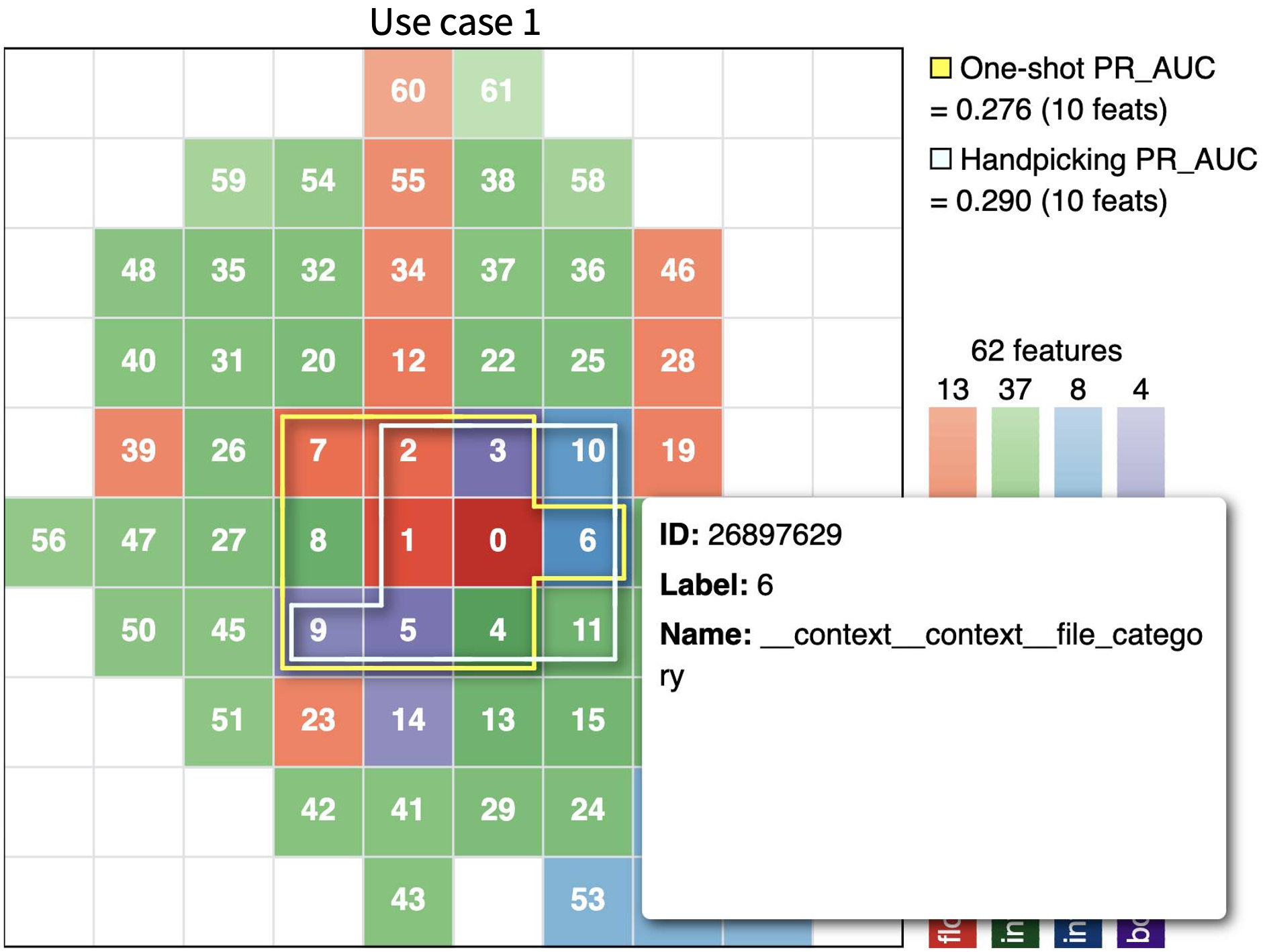
Fast and robust model-free feature selection (mRMR) for Looper, an end-to-end AI platform.
-
2021Python Feature Selection Machine Learning Deep Learning Presto Hive
-
Completed
-
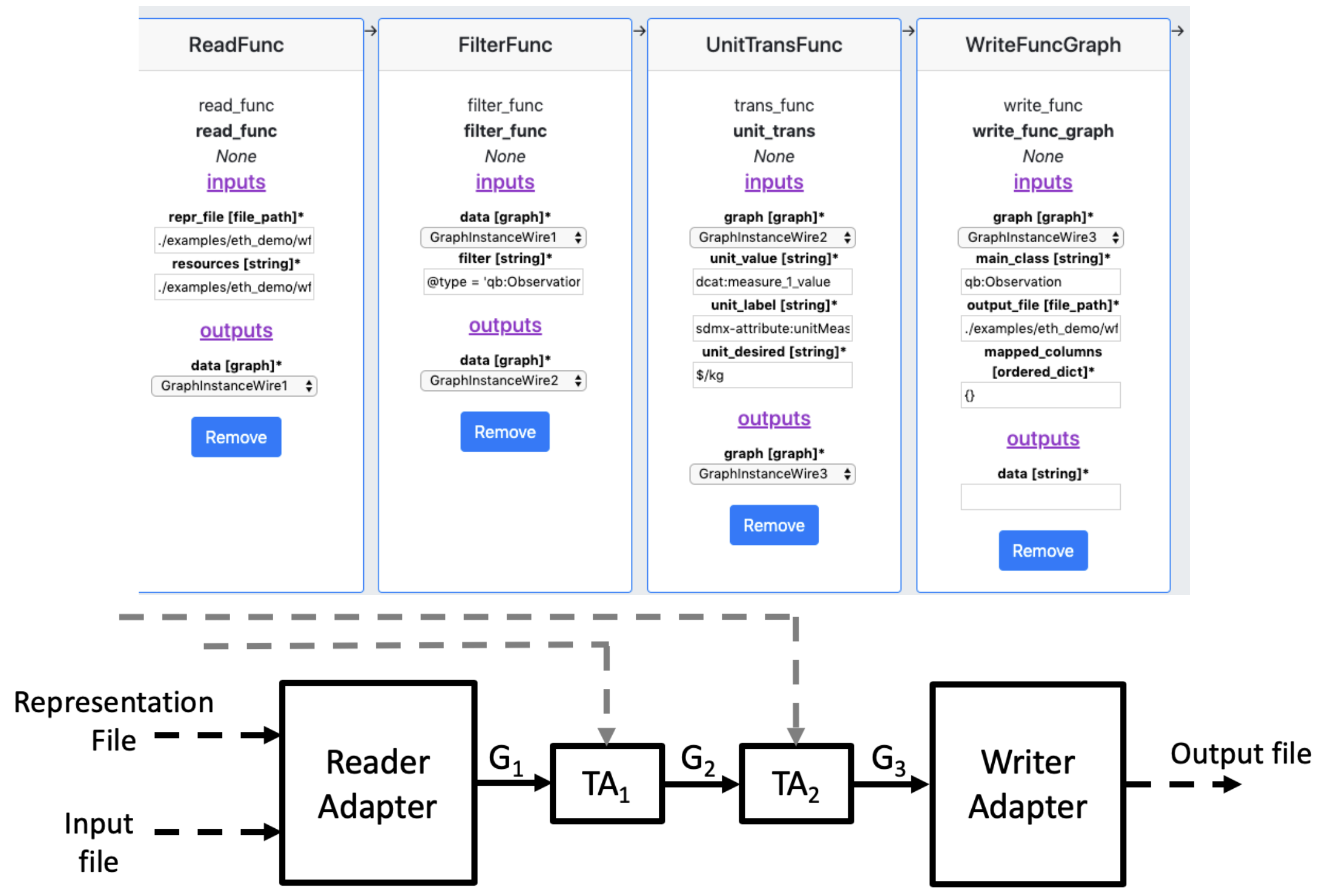
Scientific Model Integration through Knowledge-Rich Data and Process Composition. Developing a data catalog that supports querying TBs of heterogeneous data from separate disciplines (geosciences) and semi-automated data transformation.
-
2018-20Python R Semantic Web Ontology
-
Completed
-
Finding potential vulnerabilities in companies' hardware and software by mining employees' expertise in public online sources.
-
2016-17Python Java Web Crawler Machine Learning Entity Linking
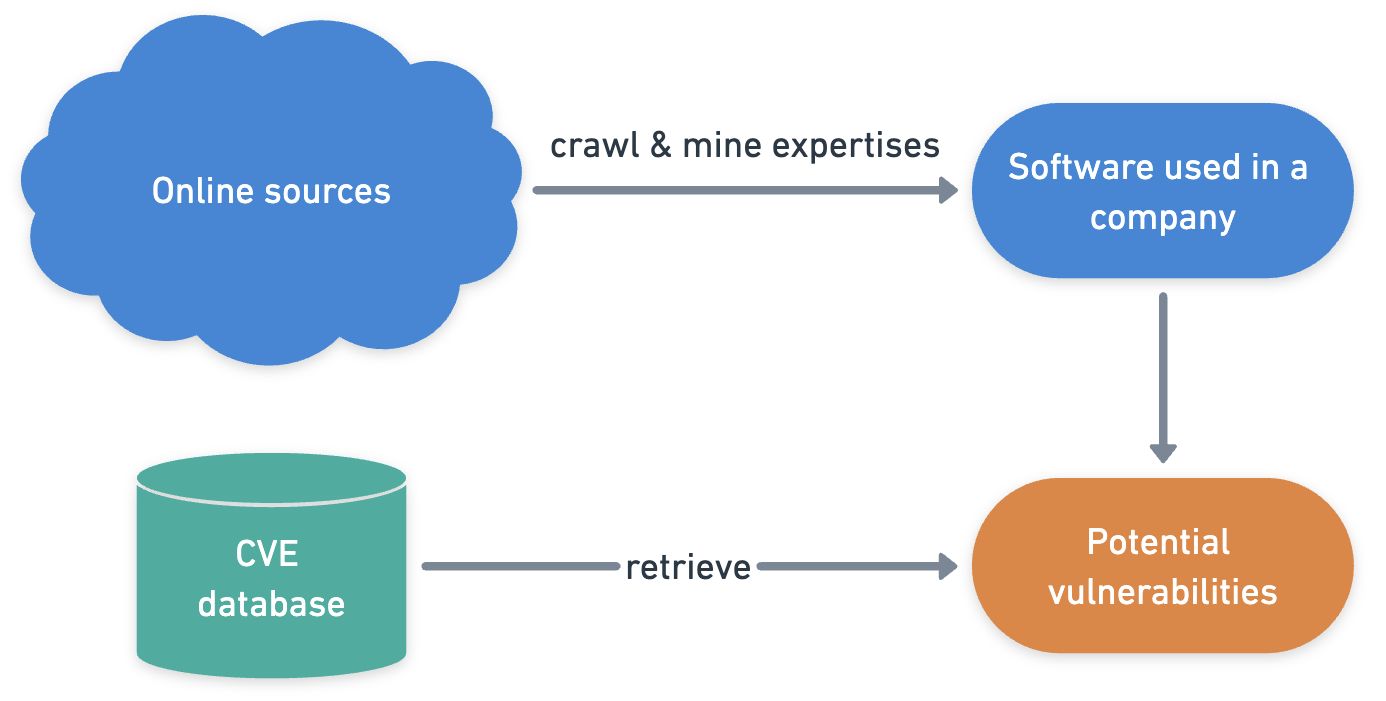
-
Completed
Large-scale Fraud Detection
at Rakuten Group Inc.
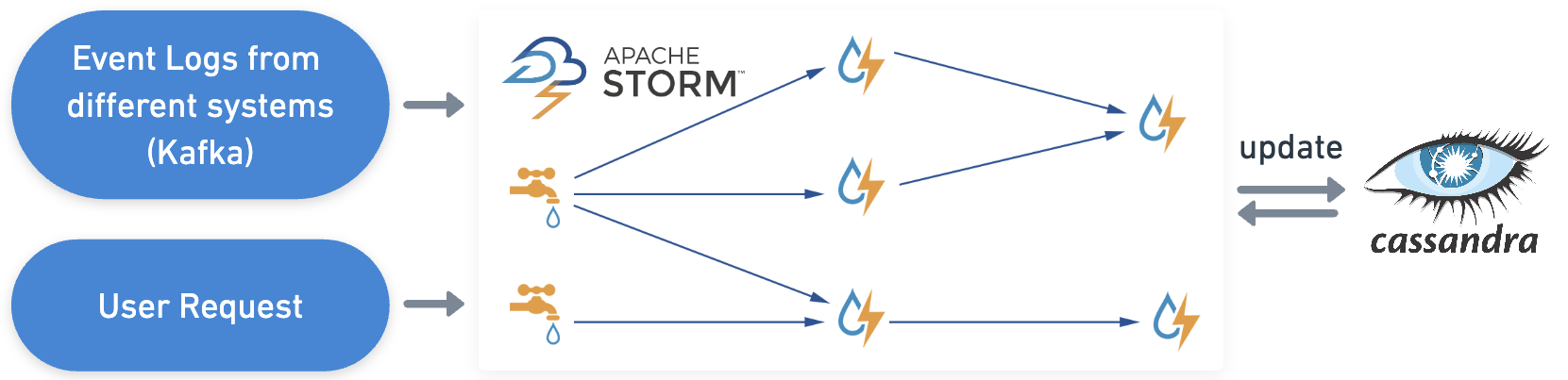
-
Near real-time distributed streaming system for detecting fraud in ID hijacking and payment within seconds.
-
2015-16Java Cassandra Apache Storm Kafka Distributed Computing
Publications
Teaching
- Teaching Assistant for DSCI 558: Building Knowledge Graphs (Graduate). Fall 2018 - Spring 2019 @ USC.
- Teaching Assistant for Artificial Intelligence (Undergraduate). Spring 2015 @ HCMUT.
Awards
- National Science Foundation sponsored Student Travel Awards
2019, The 18th International Semantic Web Conference - National Science Foundation sponsored Student Travel Awards
2017, The 16th International Semantic Web Conference - ISI Distinguished Top-Off Fellowship
2016, USC - ISI - Vietnam Education Foundation (VEF) Fellowship to pursue Ph.D. degree in the U.S
2016 - Outstanding Honor Student Award
2011 - 2014, HCMC University of Technology